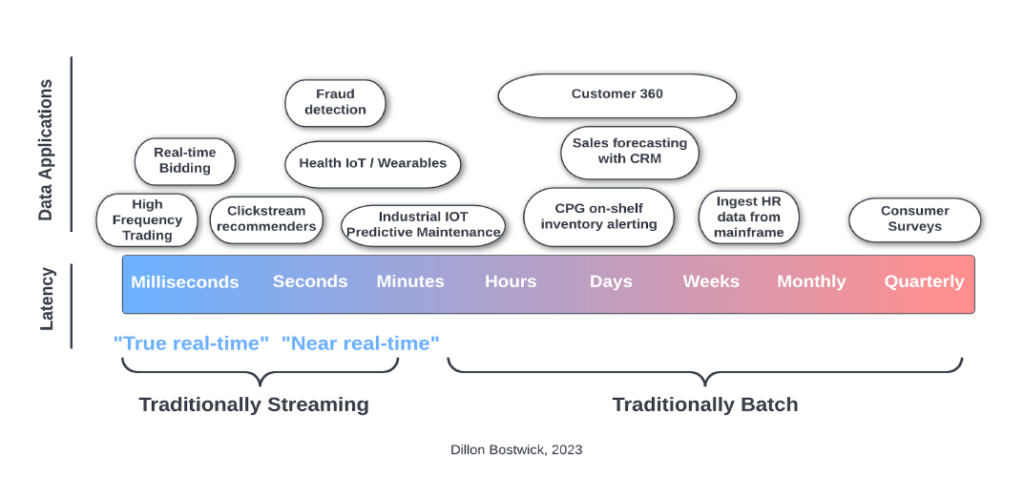
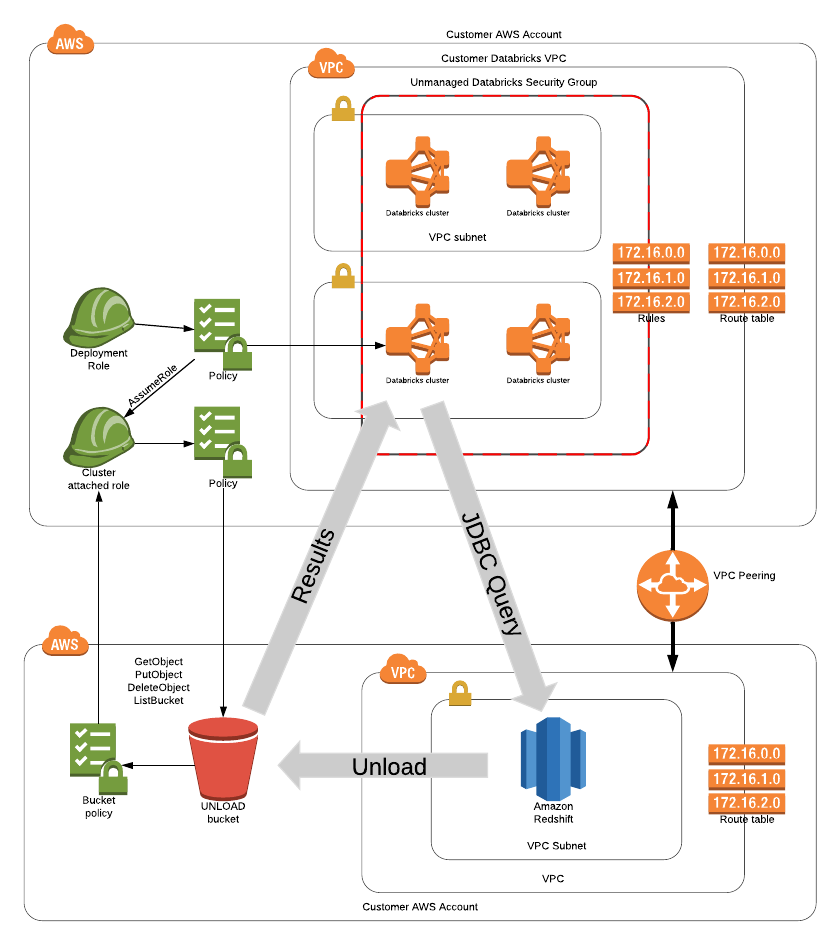
Real-Time Machine Learning
Real-Time Machine Learning
Presented at ODSC Europe 2023
General overview of tradeoffs involved in designing a production grade ML training/scoring system with event streaming. Stresses the importance of skills that intersect between data engineering, streaming, and data science.
Text to Insights
Presented at Generative AI Conference 2023
Existing SOTA techniques and limitations of text2sql with metadata augmentation, and directions for ensuring data quality and freshness with data engineering and streaming techniques

Real-Time Embedding Clustering
Published in ODSC Blog
Reference architecture and code for solving common outlier detection problems like fraud detection using embeddings. Some considerations for performing vector operations to analyze tabular data in a Spark Structured Stream.